
How Hash Tables Work: Efficient Data Lookups
In the world of computers, hash tables are like super-fast phone books. They store information like names and phone numbers (keys and values), but instead of flipping through pages, they use a special code (hash function) to jump right to the exact information you need. This code scrambles the names (keys) in a clever way, allowing for lightning-quick searches, making hash tables superstars for storing and finding data.
How It Works
Let's break down the key parts of a hash table and see why they matter.
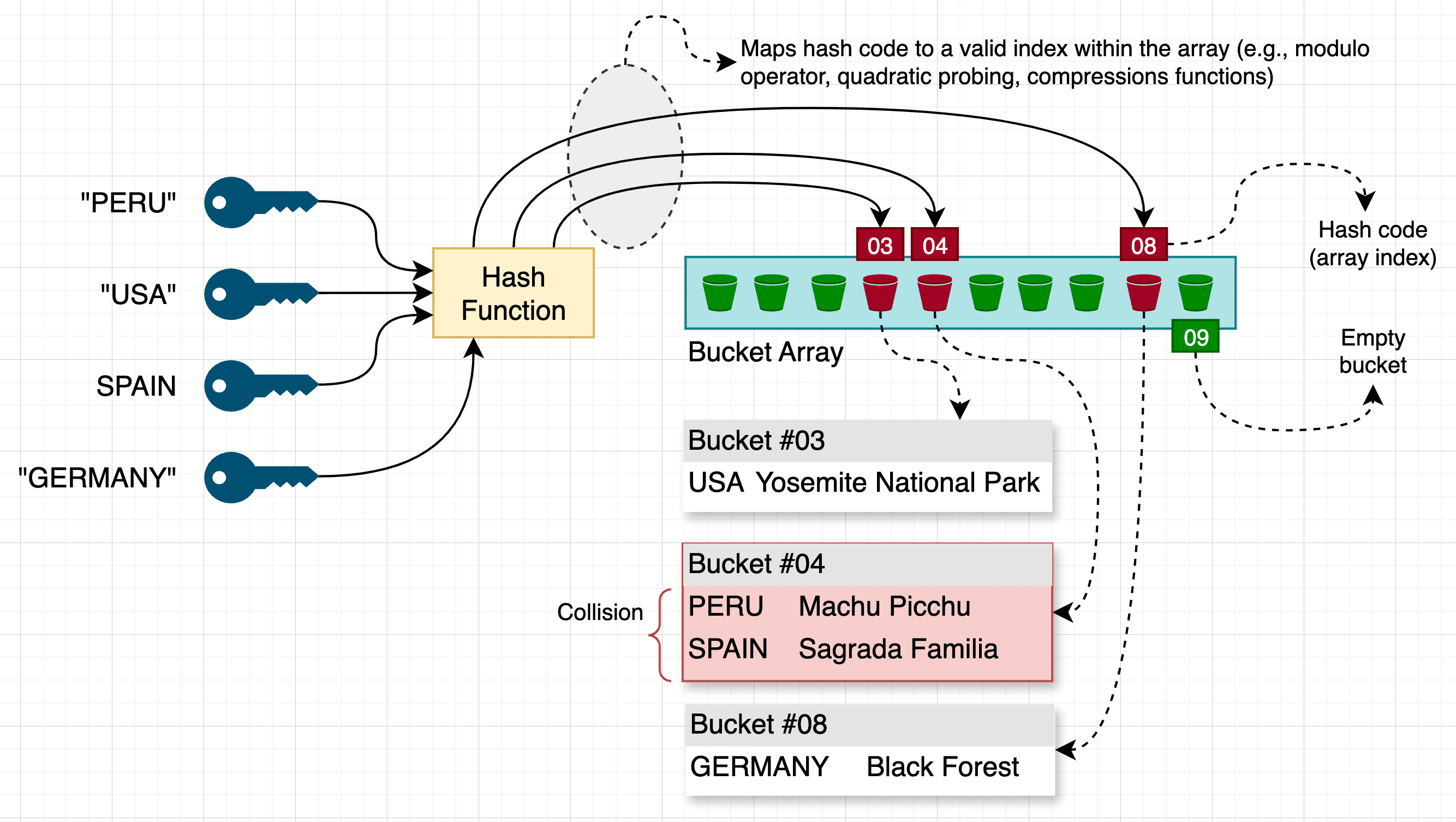
Keys and Values
Hash tables store data as key-value pairs. Unlike arrays or linked lists, which rely on a specific order or numbered positions, hash tables can use different key types such as names or descriptions. The hash function uses these keys to distribute the items.
Bucket Array
Hash tables use an array to store data. Each slot in this array, also called a bucket, can hold a single key-value pair. Sometimes, different keys might end up calculated to the same bucket (collision).
Hash Function
A hash function converts an input into a unique integer known as a hash code, which is utilized to store data in a hash table. This code, usually an integer, is modified using a modulo operation to align it with the array's size, ensuring efficient storage of data. A well-designed hash function is essential for optimizing hash table operations due to several reasons:
- Minimizes Collisions: By evenly spreading keys among buckets, it decreases the likelihood of multiple keys occupying the same slot, resulting in quicker lookups with reduced comparisons.
- Faster Lookups: With fewer collisions, the hash function quickly directs searches to the correct bucket. This ensures efficient retrieval of data, typically in constant time (O(1)).
- Simplifies Collision Resolution: When collisions are rare, handling them is simpler. This removes the need for complicated methods such as chaining with shorter linked lists, making data lookups more efficient.
On the flip side, if the hash function is poor and generates many collisions, finding data takes longer. This also makes handling those collisions more complex.
Collisions
Sometimes keys bump into each other in the hash table (collision). This is because the magic code (hash function) isn't perfect. Imagine PERU and SPAIN end up in the same spot, where Machu Picchu already is. To add Sagrada Familia, we need to sort things out first. We'll learn how hash tables handle these bumps (chaining, open addressing) later.
Load Factor
The load factor in a hash table shows how full it is. It impacts the speed of operations like insertions and lookups. A higher load factor increases collision likelihood. Keeping it below a threshold (e.g., 0.7) ensures efficient collision handling with enough empty slots.
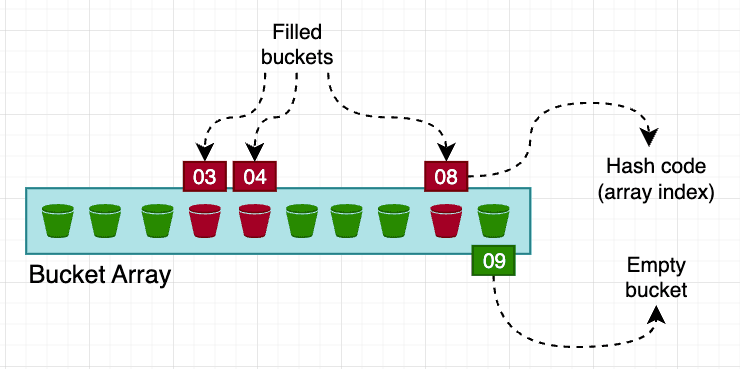
In the picture above, the load factor is 0.3, meaning the bucket array is 30% full. This is below the recommended 0.7 threshold.
Load Balancing
The goal of load balancing is to evenly distribute elements to minimize collisions and ensure that operations remain efficient. Techniques such as good hash functions, collision resolution strategies (like separate chaining or open addressing), and dynamic resizing (rehashing) contribute to achieving effective load balancing.
Deep Dive
We’ve discussed the basics of hashing, a powerful technique for organizing data. But what if keys clash during hashing? We need a way to deal with this to keep finding data fast. This is where carefully designed hashing functions and collision resolution methods come into play, guaranteeing the smooth operation of your data structures.
Hash Functions Techniques
Hashing techniques are like a smart filing system for computers. Imagine having lots of information, each labeled uniquely (i.e., key) with its own details (i.e., value). Hashing helps quickly find information based on these labels. There are primarily two categories of hashing techniques: basic hashing and cryptographic hashing.
Basic hashing techniques prioritize speed over security and are typically employed for organizing non-critical data. Let's take a look at some popular examples:
- Division Technique: Involves taking the key and dividing it by a chosen prime number (a number that can only be divided by 1 and itself). The remainder from this division is used as the hash code. While this method is efficient, it can cause grouping of hash codes (clustering) if the prime number isn't chosen carefully.
- Multiplication Technique: Multiplies the key by a special number and uses the leftover decimal part to pick a slot, giving a more even distribution than just dividing. But picking the right "special number" is important.
- Folding Technique: Splits the key into smaller, equal-sized pieces, sums them together, and adjusts the result using bitwise operations like AND or XOR to fit the required size. While useful for merging key parts, additional steps may be needed based on the key and final output sizes.
In contrast, Cryptographic Hash Functions are crafted with security in mind, serving purposes such as storing passwords securely and verifying data integrity. While they are slower compared to simple techniques, they provide crucial security features such as:
- Collision Resistance: It's very difficult to find two different inputs that produce the same hash value.
- One-Way Street: Recovering the original data from the hash is nearly impossible, keeping passwords and other secrets safe.
- Sensitive to Change: Even slight data tweaks drastically alter the hash, making tampering easily detectable.
Modern cryptographic hash functions, such as SHA-256 and MD5, use a blend of various techniques and complex operations to enhance the avalanche effect and collision resistance. The choice of hashing technique is influenced by factors such as security level, speed requirements, and the nature of the data being hashed.
Collision Resolution Techniques
Collision resolution is the process of managing situations where different keys in a hash table produce the same hash code (collision). It ensures that all keys can be stored and retrieved correctly. Common collision resolution techniques include:
Chaining
In a hash table, each bucket is a linked list that stores colliding keys, allowing multiple keys to share the same hash index. When a collision occurs, the key-value pair is added to the linked list at the corresponding index. During a lookup, the hash function determines the index, and the system traverses the linked list at that index to find the desired key-value pair. Separate chaining is a popular technique due to its simplicity and reliable insertions, though long chains from many collisions can lead to slower lookups.
Open Addressing
Keys are stored directly in the hash table itself, without using additional data structures like linked lists. Techniques include:
- Linear Probing: If a collision occurs, search sequentially for the next available slot in the hash table.
- Quadratic Probing: A quadratic function is used to determine the next probe location.
- Double Hashing: A second hash function is used to calculate the step size for probing.
In hash tables, collisions are quickly resolved by finding nearby empty slots using a probing sequence, which speeds up lookup times. However, collisions can lead to clustering in consecutive slots, slowing down lookups when probes must travel farther.
Robin Hood
The Robin Hood hashing technique is a method used to handle collisions in hash tables more efficiently, named after the legendary outlaw who took from the rich and gave to the poor. Here's how it works:
- Hash Function: Keys are hashed to an initial bucket in the hash table based on a hash function.
- Collision Handling: When a collision occurs (i.e., another key hashes to the same bucket), Robin Hood hashing compares the probe distance (how far the key has traveled from its initial bucket) of the newly inserted key with the probe distance of the key already in that bucket.
- Repositioning: If the new key has a longer probe distance (i.e., it has traveled farther), it robs the slot of the key already there and takes its place.
- Iteration: This iterative process continues for each collision encountered, aiming to minimize the longest distance keys need to be probed, ensuring more balanced performance.
Overall, Robin Hood hashing aims to minimize the worst-case scenario where some keys have significantly longer probe distances than others.
Performance considerations
In a well-designed hash table with a good hash function and the right number of slots filled (load factor), lookups, insertions, and deletions usually take a constant amount of time, noted as O(1). This means these operations are fast and don't depend on how many items are in the table (unless it's almost full). The hash function efficiently guides directly to where the data should be stored in the table. If there's no clash (collision), only one comparison is needed to find the data.
But collisions can affect this efficiency. When they happen, how we handle them matters. Different strategies, like separate chaining and open addressing, might involve extra comparisons or checks in the worst case. This could make operations take longer, possibly up to O(n) time, where n is the number of items in a collided chain (for separate chaining) or the number of checks needed in open addressing (if there's a lot of clustering).
Real World Use Cases
Hash tables are widely used in various real-world applications due to their efficiency in storing and retrieving data. Here are some common examples:
- Databases: Widely used in database indexing. They allow for fast retrieval of records based on indexed columns, improving query performance.
- Hash-based Sets and Maps: Languages like Python and JavaScript use hash tables to implement sets and maps (or dictionaries).
- Hash-based File Integrity Checking: Utilized in file integrity checks, this method stores hashes (checksums) of files to swiftly confirm file integrity and detect tampering or corruption.
- Password Storage: Employed for securely storing passwords by hashing and storing them, enabling rapid verification during login attempts without retaining the original passwords.
These applications demonstrate the versatility and efficiency of hash tables in handling various types of data storage and retrieval tasks in computer science and software engineering.
Summary
In this article, you've discovered the core components of a hash table, its operational principles, strategies for handling conflicts and real-world use cases.
Keep learning, and happy coding!